Predicting Incidents using AI
Organisation
Atlassian
Industry
IT Service Management
Year
oct 2021 - july 2022
Role
worked with a product & engineering counterpart
Background
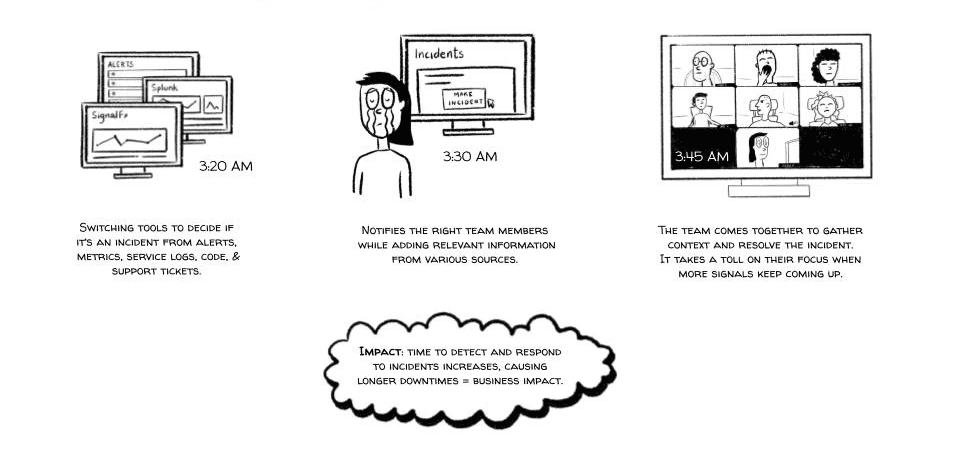
What was wrong?
Alert fatigue is common for IT and DevOps teams as they monitor the always-on technology that drives businesses.
While a single alert is easy to respond to, a dozen alerts in succession is harder. And the higher the number climbs, the more likely it is that an on-call engineer will miss something important.
There are several risks:
Missed or ignored alerts
Slow response times
Burnout
Low overall development efficiency
within atlassian
42 alerts / minute
within atlassian
1,480,000 alerts / month

it manager
"I personally file them and do not delegate it. When there are a large number of alerts,
I often end up working on weekends to ensure a good job."
Site reliability engineer
"My team often worries about large volumes of such alerts since outages could result if they are not looked at.”
sr director, service infra
"We quite often have so many Incidents filed by separate teams, although the root cause is the same. This ends up taking the time of a lot of responders."
Validating
the problem
Methods used to validate the problem
Key findings
Our competitors already had a similar feature called 'alert grouping'
These alert groups could be customised with rule-based & time-based operations
The research validated that on-call engineers often stayed up round the clock monitoring alerts
It also validated that alert storms were an indicator of an incident
technical challenges
Limited data as we were working with user-generated content
ML models had low confidence suggestions, which led to high number of false positives
How might we…
… analyse alerts to predict incidents, thereby reducing Mean Time to Respond (MTTR) for incidents?
Ideation
method used to ideate
Goals of ideation
Goal 1:
Develop a shared understanding of the problem area
Goal 2:
Think of ways to solve the problem
Ideation
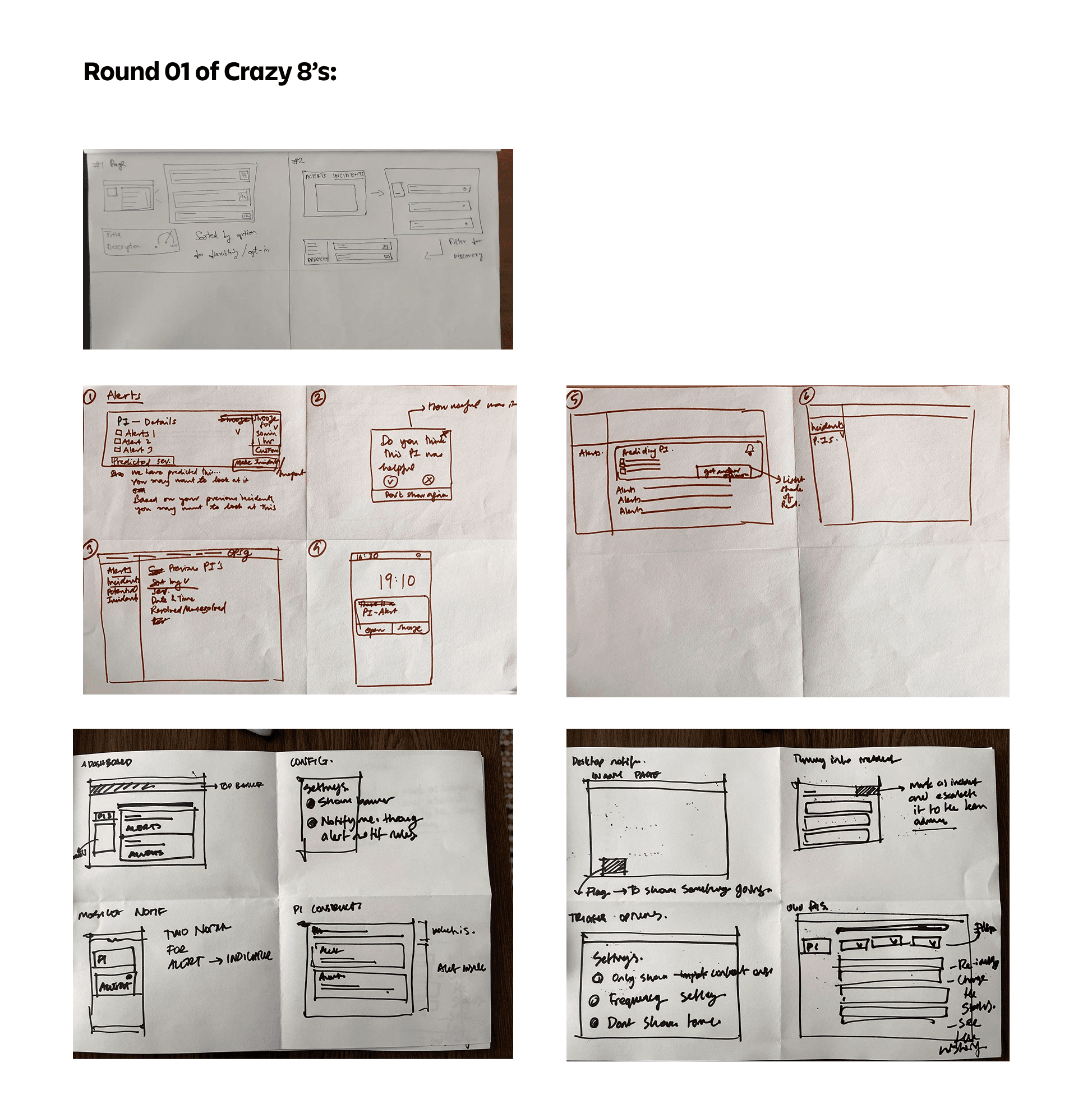

OUtcomes of the ideation session
✔️ Come up with error scenarios, non-linear solutions, crazy ideas for the problem statement and for both personas.
Designing
target personas
design challenges
design & product strategy
Enhance User Capabilities Without Disruption
Predicted incidents help on-call engineers understand situations without interfering with current workflows.
Use Familiar Concepts
The feature builds on engineers’ existing understanding of incidents, easing adoption and reducing the learning curve.
Introduce Scalable UI Patterns
A unique, recognizable UI pattern aids in user comprehension and recall.
Inclusive Design
The experience is accessible to users with varying levels of expertise, aiming to reduce entry barriers and reach a broad ITSM audience.
Build Trust and Control
Users can validate predictions themselves; no incidents are auto-created, ensuring they remain in control.
introducing a recognizable ui pattern for ai-features




View incident predictions on associated alerts

View predicted incidents under 'incidents'




Have control in your hands and turn on / off intelligent features as required
Evaluation
& Impact
method used to evaluate

key findings
Due to UGC, there were false positives, and several incidents were predicted incorrectly
Due to challenges with models, we relied on internal testing. 80% users had a positive response to this new feature.
impact
Despite being a technically challenging workstream, our team filed for several patents and published research papers
We also won internal sprints and the quarterly internal hackathon (ShipIt) within Atlassian
Being one of the first teams to create an AI feature, our learnings set the foundation for future AI work within Atlassian